개요
Residual block을 사용한 Resnet의 코드 리뷰입니다. Resnet은 Block으로 되어있기 때문에 가장 간단한 resnet18을 이해하면 나머지도 이해할 수 있습니다. 원 코드는 torchvision 코드를 참조하였습니다. 모든 resnet을 구현한 코드는 다음을 참조하시기 바랍니다.
https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
pytorch/vision
Datasets, Transforms and Models specific to Computer Vision - pytorch/vision
github.com
저는 공부하는 입장으로서 모든 분들이 최대한 이해하기 쉽도록 불필요한 코드를 제거하였습니다.
Residual Block
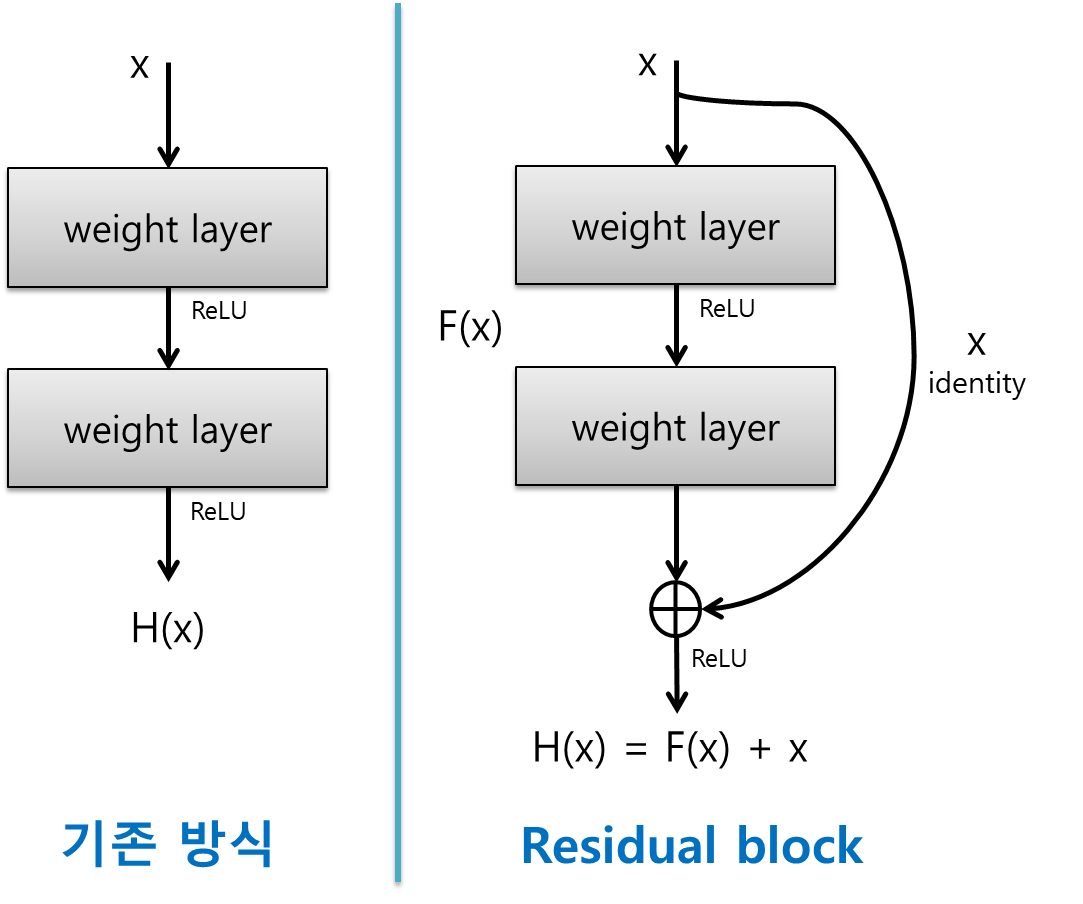
resnet의 근간이 되는 Residual block을 구현해보도록 하겠습니다.
def conv3x3(in_planes: int, out_planes: int, stride: int = 1, groups: int = 1, dilation: int = 1) -> nn.Conv2d:
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes: int, out_planes: int, stride: int = 1) -> nn.Conv2d:
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)먼저 3x3, 1x1 convolution layer를 정의해줍니다.
- in_planes : 입력 필터개수
- out_planes : 출력 필터개수
- groups : input과 output의 connection을 제어하며 1이 기본값입니다.
- dilation : 커널 원소간의 거리입니다. 늘릴수록 같은 파라미터수로 더 넓은 범위를 파악할 수 있게 됩니다. 기본값인 1을 계속 사용할겁니다.
다음은 Residual Block의 전체코드 입니다.
class BasicBlock(nn.Module):
def __init__(
self,
inplanes: int,
planes: int,
stride: int = 1,
downsample: Optional[nn.Module] = None,
groups: int = 1,
dilation: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None
) -> None:
super(BasicBlock, self).__init__()
# Normalization Layer
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
# downsampling이 필요한 경우 downsample layer를 block에 인자로 넣어주어야함
if self.downsample is not None:
identity = self.downsample(x)
out += identity # residual connection
out = self.relu(out)
return out__init__
처음에 Normalization Layer가 없는 경우 nn.BatchNorm2d로 지정해줍니다.
그 후 forward에 필요한 layer들을 정의해줍니다. 순서는 conv1, bn1, relu, conv2, bn2 순서입니다.
downsample은 forward시 f(x)+x의 residual을 구현할 경우 f(x)와 x의 텐서사이즈가 다른 경우 사용하게 됩니다.
forward
forward는 간단합니다. identity 변수에 입력텐서 x를 저장하고
정의해둔 신경망을 거친 뒤, out과 identity(입력텐서)를 더한 후 relu를 거치게 됩니다.
아까 말한대로 downsampling이 필요한 경우 다운샘플링을 하게 됩니다.
downsample layer는 Resnet Class에서 정의하여 넣어주게 됩니다.
ResNet Class
Resnet class의 전체 코드입니다.
class ResNet(nn.Module):
def __init__(
self,
block: Type[Union[BasicBlock, Bottleneck]],
layers: List[int],
num_classes: int = 1000,
zero_init_residual: bool = False,
norm_layer: Optional[Callable[..., nn.Module]] = None
) -> None:
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer # batch norm layer
self.inplanes = 64 # input shape
self.dilation = 1 # dilation fixed
self.groups = 1 # groups fixed
# input block
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# residual blocks
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=False)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=False)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=False)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
# weight initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0) # type: ignore[arg-type]
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0) # type: ignore[arg-type]
def _make_layer(self, block: Type[Union[BasicBlock, Bottleneck]], planes: int, blocks: int,
stride: int = 1, dilate: bool = False) -> nn.Sequential:
norm_layer = self._norm_layer
downsample = None
# downsampling 필요할경우 downsample layer 생성
if stride != 1 or self.inplanes != planes:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes, stride),
norm_layer(planes),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.dilation, norm_layer))
self.inplanes = planes
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def forward(self, x: Tensor) -> Tensor:
print('input shape:', x.shape)
x = self.conv1(x)
print('conv1 shape:', x.shape)
x = self.bn1(x)
print('bn1 shape:', x.shape)
x = self.relu(x)
print('relu shape:', x.shape)
x = self.maxpool(x)
print('maxpool shape:', x.shape)
x = self.layer1(x)
print('layer1 shape:', x.shape)
x = self.layer2(x)
print('layer2 shape:', x.shape)
x = self.layer3(x)
print('layer3 shape:', x.shape)
x = self.layer4(x)
print('layer4 shape:', x.shape)
x = self.avgpool(x)
print('avgpool shape:', x.shape)
x = torch.flatten(x, 1)
print('flatten shape:', x.shape)
x = self.fc(x)
print('fc shape:', x.shape)
return x더 자세히 살펴보도록 하겠습니다.
__init__
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer # batch norm layer
self.inplanes = 64 # input shape
self.dilation = 1 # dilation fixed
self.groups = 1 # groups fixed
# input block
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)__init__ 부분입니다. 아까와 같이 Normalization Layer가 없는 경우 생성해줍니다.
inplanes, dilation, groups는 각각 64, 1, 1로 고정해줍니다.
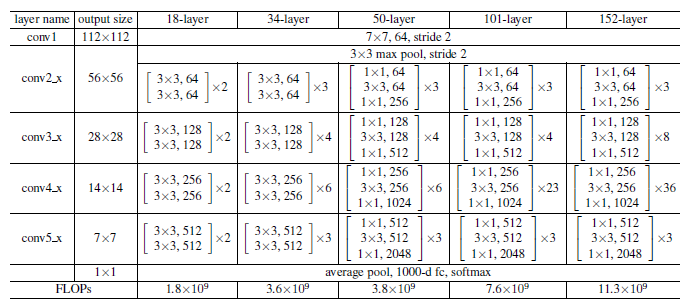
맨 위 이미지의 resnet 구조를 보시면 7x7 conv와 3x3 max pooling이 있는데 이 부분은 그 구조를 구현한 코드입니다.
# residual blocks
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=False)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=False)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=False)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
그 다음 단계는 self._make_layer를 이용하여 residual block들을 쌓게 됩니다. 필터의 개수는 각 block들을 거치면서 2배씩 늘어나게 됩니다.(64->128->256->512)
모든 block을 거친 후에는 Adaptive AvgPool2d를 적용하여 (n, 512, 1, 1)의 텐서로 만듭니다.
이후 fc layer를 연결하면 끝입니다.
_make_layer
def _make_layer(self, block: Type[Union[BasicBlock, Bottleneck]], planes: int, blocks: int,
stride: int = 1, dilate: bool = False) -> nn.Sequential:
norm_layer = self._norm_layer
downsample = None
# downsampling 필요할경우 downsample layer 생성
if stride != 1 or self.inplanes != planes:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes, stride),
norm_layer(planes),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.dilation, norm_layer))
self.inplanes = planes
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)_make_layer에서는 residual block을 생성하게 됩니다.
- block : BasicBlock 구조 사용
- planes : input shape
- blocks : layer 반복해서 쌓는 개수
- stride, dilate : 고정
중간에 downsampling layer를 생성하는 부분이 있습니다. stride가 1이 아니라서 크기가 줄어들 경우 혹은
self.inplanes가 planes의 크기와 맞지 않을때 conv1x1에 1이 아닌 stride를 가진 레이어로 downsampling을 하게 됩니다.
그 후 입력받은 block을 입력받은 blocks 개수만큼 쌓게 됩니다. 처음에 한번 따로 쌓아주는 이유는 첫 block을 쌓고 self.inplanes를 planes와 맞춰주기 위함입니다.
Forward
forward 부분은 텐서의 사이즈 변화를 나타내기 위해 레이어 별로 사이즈를 출력하도록 했습니다.
Model 생성 및 테스트
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)모델출력결과, residual block이 4개가 생성되었음을 확인할 수 있습니다.

모델 생성 후 랜덤으로 생성한 input tensor의 출력 결과입니다.
'AI' 카테고리의 다른 글
| TransUNet - Transformer를 적용한 Segmentation Model 논문 리뷰 (0) | 2021.02.25 |
|---|---|
| Vision Transfromer (ViT) Pytorch 구현 코드 리뷰 - 3 (2) | 2021.02.22 |
| Vision Transfromer (ViT) Pytorch 구현 코드 리뷰 - 2 (2) | 2021.02.22 |
| Vision Transfromer (ViT) Pytorch 구현 코드 리뷰 - 1 (3) | 2021.02.19 |
| Semantic Segmentation information Links (0) | 2021.02.19 |