개요
2021년 3월 5일에 Facebook AI Research 팀에서 발표된 논문입니다.
논문 원제는 Self-supervised Pretraining of Visual Features in the Wild 입니다.
arxiv.org/pdf/2103.01988v2.pdf
최근에 Self-Supervised Learning(자기지도학습) 분야는 꽤 발전해서 SimCLR, BYOL, SwAV의 방법들은 Supervised Learning과의 격차를 매우 좁혔습니다. 이 논문에서는 SElf-supERvised(SEER) 모델을 제시합니다. SEER는 Self-Supervised Learning 방법으로 SwAV를 사용하였고 모델 Architecture는 RegNetY를 사용하였으며 가장 큰 특징은 랜덤하게 가져온 2B개의 uncurated 인스타그램 이미지들을 사용하여 학습하였다는 사실입니다. 그 결과로 다른 자기지도학습 모델들보다 뛰어난 성능을 나타냈습니다.
관련연구
1. Unsupervised Pretraining of visual features.
Unsupervised Learning은 오토인코더, 클러스터링, instance-level 구별 등의 방법을 써왔지만 최근의 트렌드는 contrastive learning 입니다. 간단하게 설명하자면 이미지에 서로 다른 augmentaion을 적용하여 각 feature를 뽑고 뽑은 feature들에 MLP를 적용한 벡터들을 비교하여 같은 사진은 유사도를 크게, 다른 사진은 유사도를 낮게하여 학습하는 방법입니다. 지금까지는 보통 ImageNet과 같은 curated된 다른 데이터셋을 이용해 학습했지만 논문에서는 랜덤하고 uncurated, unlabeled된 이미지들을 사용하였습니다.
2. Scaling architectures for image recognition.
많은 연구들은 더 좋은 Visual Features를 뽑아내는데 더 큰 아키텍처가 이점이 있다는 사실을 보여줬습니다. 이는 Underfit 될 가능성이 있는 큰 데이터셋에서 사전학습시에 특히 더 중요합니다. 따라서 Contrastive Learning에서도 더 크고 넓은 모델이 좋은 성능을 보인다고 합니다. 하지만 단순히 모델의 크기를 키우는게 아니라 효율적으로 키우는 것도 중요합니다. RegNets는 효율적인 런타임과 메모리사용량을 가지기 때문에 논문에서 Self-Supervised Pretraining을 위한 모델로 차용되었습니다.
연구방법
1. Self-Supervised Pretraining(SwAV)
논문에서 자기지도학습 방법으로 사용된 SwAV는 기존의 Contrastive Learning 방법과 다르게 Multi-View Image들의 일관된 Cluster 할당을 위해 임베딩 벡터들을 훈련시킵니다. 즉 아래와 같이 다른 Augmentation을 적용한 이미지들의 Feature들을 중간단계의 Cluster들을 이용해 비교합니다.

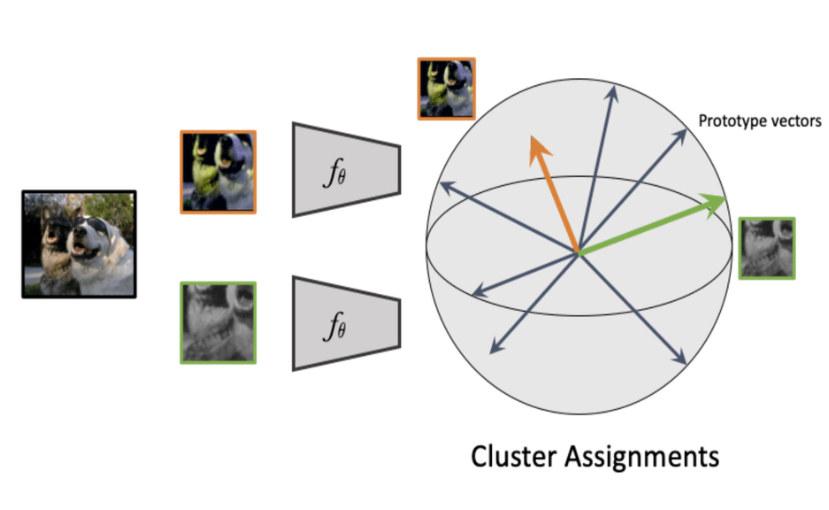
과정을 간단하게 설명하면 B개의 배치가 있을때 각 이미지들은 $x_{i1}, x_{i2}$인 2개의 view로 나뉩니다. 모든 view는 ConvNet을 통해 특징을 뽑게되고, 2개의 feature $(f_{11}, ..., f_{B1}, and f_{12}, ... , f_{B2})$가 나옵니다. 그리고 각 feature들을 cluster prototype vector들에 독립적으로 할당하여 Code를 생성합니다. 이제 Swap할 차례입니다. 이미지 $x_{i1}$으로부터 클러스터가 할당된 $y_{i1}$은 다른 이미지인 $x_{i2}$에서 뽑은 feature $f_{i2}$로부터도 Predicted 되어야 합니다. 역도 마찬가지입니다. 이걸 식으로 표현하면 다음과 같습니다.

ConvNet과 Prototype Weights들은 모든 $i$에 대하여 위 식의 Loss를 최소화하는 방향으로 학습되게 됩니다. Prediction Loss $l(f, y)$은 (Cluster Assginment $y$)와 ($f$와 모든 프로토타입 $v_k$를 내적한 후 Softmax를 적용한 $p$) 사이의 Cross Entropy입니다.


2. RegNetY
데이터와 모델크기의 조정은 메모리와 런타임이 효율적일 필요가 있습니다. RegNets는 이 목적으로 디자인된 모델들의 Family입니다. RegNet은 4개의 스테이지로 구성되어 있으며 각 스테이지는 연속적인 동일블럭들로 구성되어 있습니다. 이 논문에서는 RegNets에 Squeeze-and-excitation Operation을 추가한 RegNetY Architecture를 사용했습니다. 그 중 RegNetY-256GF는 stage depth가 (2, 7, 17, 1)로 구성되어있고 각 너비는 (528, 1056, 2904, 7392)이며 총 파라미터수는 695.5M개입니다. 512개의 V100 32GB GPU로 8,704개의 이미지를 한 이터레이션 학습시키는데 6125ms가 소비된다고 합니다.
3. Optimization and Training at Scale
- Learning Rate는 cosine learnig rate schedule이 사용되었습니다.
- 인스타그램의 Random, public, non-EU 이미지들을 학습데이터로 사용하였고 어느 필터링이나 중복제거를 하지 않고 사용했습니다.
- 데이터셋은 고정되있지 않으며 90일마다 refreshment됩니다. 하지만 이것은 모델의 성능에 낮추거나 하지 않습니다.
- 이미지당 6개로 잘라내어(Multi-Crop) SwAV와 RegNetY-256GF를 이용해 학습했습니다.
- 3-layer의 MLP Projection Head를 이용했으며 dimension은 10444 x 8192, 8192 x 8192, 8192 x 256 입니다.
실험결과

다른 Self-Supervised 모델들과의 비교결과입니다. 이전의 가장 성능이 좋은 Self-Supervised pretraining 모델인 SimCLRv2보다 1% 가까운 차이를 보여줍니다.

Model Capacity가 커질수록 scratch(처음)부터 시작한 것과의 차이가 커집니다. 즉 큰 모델일수록 Pretrained 모델이 더 좋은 성능을 내는 것을 확인할 수 있습니다.

ImageNet에서 Low-Shot 학습의 비교 결과입니다. 여기서 중요한 점은 다른 모델들은 ImageNet에서 Pretrained 되었지만 SEER 모델은 Random Internet 이미지들로 학습되었음에도 약간의 성능차이만을 보입니다.

Low-Shot 학습에서의 모델 크기별 상대적인 정확도 비교결과입니다. 더 적은 학습데이터를 쓴다고 가정할 경우 모델이 커지면 커질수록 더 높은 정확도를 보이게 됩니다.
그리고 다른 Task인 Detection, Segmentation과 Weakly-Supervised Pretraining과 비교했을때도 좋은 결과를 보였습니다. 자세한 결과는 원 논문을 참고바랍니다.
결론
랜덤이미지들을 아무런 정보없이 pretraining 시켜 다양한 downstram task에 좋은 결과를 보여줬습니다. 결론적으로는 curated된 데이터셋인 ImageNet 등을 self-supervised 하지 않고 uncurated data를 사용해도 benefit을 얻을 수 있습니다. RegNets의 확장성은 self-supervised pretraining의 한계까지 이끌어내는데 중요한 역할을 했으며 더 큰 RegNet 구조를 사용하는 것을 계획하고 있다고 합니다.
'AI' 카테고리의 다른 글
| Perceiver IO 논문 리뷰 (0) | 2021.09.24 |
|---|---|
| YOLO v5 Pretrained Pytorch 모델 사용하기 (7) | 2021.03.26 |
| Lambda Networks 논문 리뷰 (0) | 2021.03.02 |
| TransUNet - Transformer를 적용한 Segmentation Model 논문 리뷰 (0) | 2021.02.25 |
| Vision Transfromer (ViT) Pytorch 구현 코드 리뷰 - 3 (2) | 2021.02.22 |