개요
ultralytics/yolov5
YOLOv5 in PyTorch > ONNX > CoreML > TFLite. Contribute to ultralytics/yolov5 development by creating an account on GitHub.
github.com
Multiple Object Detection을 위해 고안된 모델인 YOLO v5를 사용해보겠습니다. 사용시 다른 프로젝트에서 쉽게 적용할 수 있도록 Model Load와 Image Predction 부분만 실행되도록 detect.py 코드를 수정했습니다.
Visual Studio Code, Git, Ananconda(파이썬 가상환경 관리)가 설치되어있고 VS Code에서 Anaconda 가상환경을 사용할 수 있어야 합니다.
Git Clone
먼저 Anaconda를 이용해 새로운 파이썬 가상환경을 만듭니다. 만들었다면 VS Code에서 명령어 팔레트(Ctrl+Shift+p)를 열고 Git Clone을 이용해 위 링크의 코드를 다운로드 받습니다.

pip install -r requirements.txt이후 클론을 다운받은 위치에서 터미널을 열어 위와 같은 명령어를 입력해 모든 필요 패키지들을 설치해줍니다.
Simplify detect.py

Inference시 detect.py를 통하여 모델 load 및 inference, 결과데이터 저장 등을 하게됩니다. 따라서 detect.py를 수정하여 최소한의 기능만 남기고 간소화하도록 하겠습니다.
detect.py가 위치하는 폴더에 detect_simple.py를 생성하고 아래 코드를 복사해주세요. argparse와 dataset 클래스, 로그저장, 결과저장 등의 불필요한 부분을 제거하고 모델로드, 추론, 결과출력만 남긴 코드입니다. 참고로 지정한 WEIGHTS가 존재하지 않을 경우 자동적으로 다운받게 됩니다. 모델은 s, m, l, x가 있습니다.
import time
import cv2
import torch
import torch.backends.cudnn as cudnn
import numpy as np
from numpy import random
from models.experimental import attempt_load
from utils.datasets import letterbox
from utils.general import check_img_size, check_requirements, non_max_suppression, scale_coords
from utils.plots import plot_one_box
from utils.torch_utils import select_device, time_synchronized
SOURCE = 'data/images/bus.jpg'
WEIGHTS = 'yolov5s.pt'
IMG_SIZE = 640
DEVICE = ''
AUGMENT = False
CONF_THRES = 0.25
IOU_THRES = 0.45
CLASSES = None
AGNOSTIC_NMS = False
def detect():
source, weights, imgsz = SOURCE, WEIGHTS, IMG_SIZE
# Initialize
device = select_device(DEVICE)
half = device.type != 'cpu' # half precision only supported on CUDA
print('device:', device)
# Load model
model = attempt_load(weights, map_location=device) # load FP32 model
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(imgsz, s=stride) # check img_size
if half:
model.half() # to FP16
# Get names and colors
names = model.module.names if hasattr(model, 'module') else model.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in names]
# Run inference
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
# Load image
img0 = cv2.imread(source) # BGR
assert img0 is not None, 'Image Not Found ' + source
# Padded resize
img = letterbox(img0, imgsz, stride=stride)[0]
# Convert
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Inference
t0 = time_synchronized()
pred = model(img, augment=AUGMENT)[0]
print('pred shape:', pred.shape)
# Apply NMS
pred = non_max_suppression(pred, CONF_THRES, IOU_THRES, classes=CLASSES, agnostic=AGNOSTIC_NMS)
# Process detections
det = pred[0]
print('det shape:', det.shape)
s = ''
s += '%gx%g ' % img.shape[2:] # print string
if len(det):
# Rescale boxes from img_size to img0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], img0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
label = f'{names[int(cls)]} {conf:.2f}'
plot_one_box(xyxy, img0, label=label, color=colors[int(cls)], line_thickness=3)
print(f'Inferencing and Processing Done. ({time.time() - t0:.3f}s)')
# Stream results
print(s)
cv2.imshow(source, img0)
cv2.waitKey(0) # 1 millisecond
if __name__ == '__main__':
check_requirements(exclude=('pycocotools', 'thop'))
with torch.no_grad():
detect()
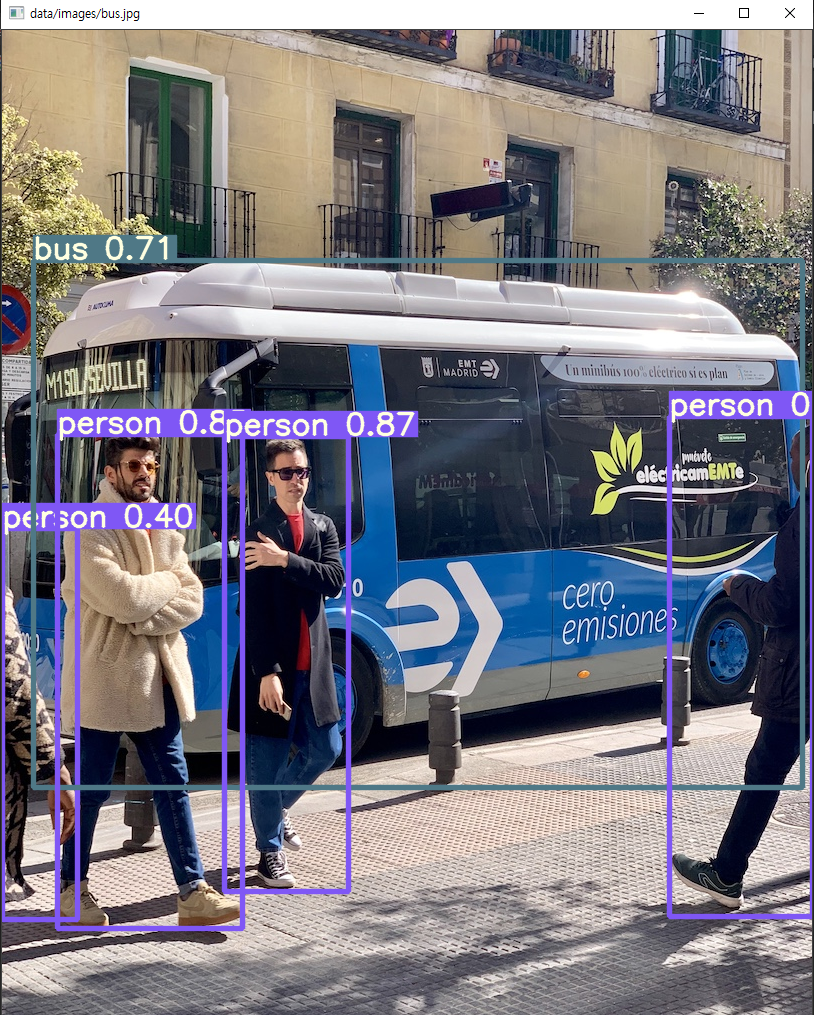
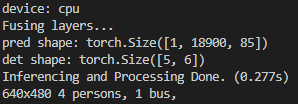
위와 같이 한장의 이미지를 입력하면 inference 후 opencv를 이용해 결과를 나타냅니다.
코드분석
간단하게 코드를 분석해보겠습니다.
import time
import cv2
import torch
import torch.backends.cudnn as cudnn
import numpy as np
from numpy import random
from models.experimental import attempt_load
from utils.datasets import letterbox
from utils.general import check_img_size, check_requirements, non_max_suppression, scale_coords
from utils.plots import plot_one_box
from utils.torch_utils import select_device, time_synchronized
SOURCE = 'data/images/bus.jpg'
WEIGHTS = 'yolov5s.pt'
IMG_SIZE = 640
DEVICE = ''
AUGMENT = False
CONF_THRES = 0.25
IOU_THRES = 0.45
CLASSES = None
AGNOSTIC_NMS = False필요한 모듈로드 및 상수설정입니다. CONF_THRES와 IOU_THRES는 모델 prediction이후 바운딩 박스를 조절하는 NMS(Non-Max-Suppresion)에 사용되는 threshold 값입니다. 기본값으로 설정했습니다.
CLASSES는 분류 필터링을 할 경우 사용하고 AGNOSTIC_NMS는 Classification없이 물체의 바운딩 박스만을 찾고 싶을때 사용하게 됩니다.
def detect():
source, weights, imgsz = SOURCE, WEIGHTS, IMG_SIZE
# Initialize
device = select_device(DEVICE)
half = device.type != 'cpu' # half precision only supported on CUDA
print('device:', device)
# Load model
model = attempt_load(weights, map_location=device) # load FP32 model
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(imgsz, s=stride) # check img_size
if half:
model.half() # to FP16
# Get names and colors
names = model.module.names if hasattr(model, 'module') else model.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in names]
# Run inference
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once디바이스 선택 후 모델을 로드하고 이미지 사이즈를 stride로 나눌 수 있는지 체크해줍니다. 그 다음엔 class name을 설정해주고 각 클래스 별로 RGB 컬러를 랜덤으로 지정합니다. 이후 torch zero Tensor를 생성하여 Inference를 한번 해주게 됩니다.
# Load image
img0 = cv2.imread(source) # BGR
assert img0 is not None, 'Image Not Found ' + source
# Padded resize
img = letterbox(img0, imgsz, stride=stride)[0]
# Convert
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
print(img.shape, img0.shape)
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)이미지 로드하는 부분입니다. 아까 설정한 source에서 이미지를 읽고 이미지가 없을 경우 예외처리를 시킵니다. letterbox를 이용해 패딩을 해주고 opencv는 BGR 체계이기 때문에 RGB로 바꿔줍니다. 또한 pytorch의 경우 모델에 입력할 경우 채널차원이 맨 앞에 있어야 하기때문에 transpose를 적용하게 됩니다.
이후, numpy array에서 torch Tensor형식으로 변환하고 torch 모델의 입력은 항상 배치형태로 받기 때문에 맨 앞에 차원을 하나 넣어주게됩니다. 최종적으로는 1 x 3 x IMG_COL x IMG_ROW의 사이즈가 나오게됩니다.
# Inference
t0 = time_synchronized()
pred = model(img, augment=AUGMENT)[0]
print('pred shape:', pred.shape)
# Apply NMS
pred = non_max_suppression(pred, CONF_THRES, IOU_THRES, classes=CLASSES, agnostic=AGNOSTIC_NMS)
# Process detections
det = pred[0]
print('det shape:', det.shape)model에 이미지를 입력하면 pred가 나오게 됩니다. pred의 형태는 torch.Size([1, 18900, 85])가 나오게 됩니다. Yolo 모델은 각 이미지를 그리드 셀로 나누어 바운딩 박스들의 위치와 Confidence, Class 확률정보가 나오게 됩니다. 따라서 그리드 셀에서 18900개의 바운딩 박스를 예측한 것을 확인할 수 있습니다. 위 코드에서 pred를 직접 출력해보시면 아시겠지만 index 0~3은 바운딩 박스의 위치, index 4는 바운딩 박스의 Confidence Score, 나머지 80개는 클래스들의 확률을 나타냅니다.
이후 NMS를 적용하면 threshold가 넘는 같은 클래스의 바운딩 박스들이 합쳐져 나오게 됩니다. torch.Size([5, 6])의 형식으로 나오게 되며 5는 예측한 바운딩박스의 개수, 두번째 차원의 6개의 벡터는 $(x_1, y_1), (x_2, y_2)$ 좌표, Confidence Score, 분류된 클래스로 이루어져 있습니다.
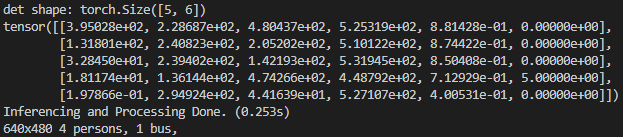
det을 출력해보면 앞 4개는 xy좌표들이고, 4번째는 정확도, 마지막은 클래스입니다. 마지막 클래스는 0이 4개고 5가 1개 존재하는데 사람 클래스가 4개, 버스 클래스가 1개 나오는 것을 확인할 수 있습니다.
s = ''
s += '%gx%g ' % img.shape[2:] # print string
if len(det):
# Rescale boxes from img_size to img0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], img0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
label = f'{names[int(cls)]} {conf:.2f}'
plot_one_box(xyxy, img0, label=label, color=colors[int(cls)], line_thickness=3)
print(f'Inferencing and Processing Done. ({time.time() - t0:.3f}s)')det에서 나온 xy좌표들을 img0 사이즈에 맞게 리스케일링 해주고 img0 이미지에 예측한 클래스들과 정확도 등을 plot_one_box 함수를 이용하여 그려주게 됩니다.
# Stream results
print(s)
cv2.imshow(source, img0)
cv2.waitKey(0) # 1 millisecond마지막으로 opencv를 이용해 예측된 이미지를 띄워줍니다.
'AI' 카테고리의 다른 글
| Donut : Document Understanding Transformer without OCR 논문리뷰 (0) | 2021.12.06 |
|---|---|
| Perceiver IO 논문 리뷰 (0) | 2021.09.24 |
| SEER - Pretrainig of Visual Features in the Wild 논문 리뷰 (0) | 2021.03.23 |
| Lambda Networks 논문 리뷰 (0) | 2021.03.02 |
| TransUNet - Transformer를 적용한 Segmentation Model 논문 리뷰 (0) | 2021.02.25 |