
Abstract
2021년 11월 30일에 네이버 Clova AI 연구팀에서 제출된 논문입니다.
기존의 Visual Document Understanding(VDU)은 OCR을 base로 해서 동작하였기 때문에 계산 cost가 높고 OCR Error에 의한 성능하락이 있어왔습니다. 따라서 해당 논문에서는 OCR 프레임워크가 base에 없는 end-to-end 방식의 새로운 VDU 모델을 제안합니다. 또한 large-scale의 실제 문서이미지에 대한 의존을 줄이기 위해서 Synthetic Document Generator(SynthDog)도 같이 소개하며, 이를 이용해 모델을 pretrain 하였다고 합니다. Donut은 다양한 공공 및 사적 데이터셋들에 대해 시행한 Document Understanding 과제에서 추론속도를 단축함과 동시에 SOTA 성능을 달성했습니다.

Introduction
VDU는 문서의 다양한 형식, 레이아웃, 내용 등에 대해서 문서를 이해하는 과제이고 문서처리 자동화 과정에서 매우 중요합니다. 이러한 과정에는 Classification, Parsing, Visual Quetion Answering(VQA) 등이 있습니다.
현재까지 대부분의 VDU 시스템들은 비슷한 구조를 공유하고 있는데 먼저 독립된 OCR 모듈을 이용해 문서이미지에서 text 정보를 추출한 후 이 정보를 입력으로 사용하여 과제를 수행한다는 점입니다.
하지만 실제로 이런 구조는 몇가지 문제가 있는데, 첫번째는 OCR은 학습비용이 많이들고 기존의 OCR 모듈은 만족할만한 성능이 나오지 않을수도 있다는 점입니다. 두번째는 OCR의 에러가 후속 과정까지 영향을 미쳐 성능을 저하하게 됩니다. 특히 한국어나 일본어같이 복잡하고 다양한 문자로 되어있을때 더욱 영향이 큽니다.
따라서 Donut은 raw 입력이미지로부터 이상적인 출력으로 바로 맵핑을 하는 ent-to-end 구조로 되어있습니다. 논문에서 같이 제안된 SynthDoG는 실제문서 데이터셋에 대한 의존도를 줄이게 해주는 문서합성기이며, Donut은 SynthDog를 이용해 pre-training 되었습니다.
Method

Document Understanding Transformer(Donut)은 간단한 Transformer base의 encoder-decoder 모델입니다. E2E 모델로써 OCR과 같은 다른모듈에 의존적이지 않습니다. Donut은 Visual Encoder와 Textural Decoder 모듈로 이루어져 있으며, 모델은 입력된 문서이미지를 바로 구조화된 출력과 1대1로 대응되는 연속된 토큰들을 생성합니다.
Encoder
Visual Encoder는 입력이미지 $\mathbf{x}\in\mathbb{R}^{{H}\times{W}\times{C}}$를 $\left\{\mathbf{z}_{i}|\mathbf{z}_{i}\in\mathbb{R}^{d}, {1}\leq{i}\leq{n} \right\}$로 임베딩 합니다. $n$은 feature map의 사이즈 또는 이미지 패치들의 개수이며, $d$는 인코더의 latent 벡터들의 차원입니다.
인코더는 ResNet과 같은 CNN-based 모델이나 Transformer-based 모델을 사용할 수 있습니다. 논문에서는 예비연구를 할 때 Document Parsing에서 가장 좋은 성능을 보인 Swin Transformer 인코더를 사용했습니다.
Decoder
$\left\{\mathbf{z} \right\}$가 주어졌을때, Textual Ecoder는 토큰 시퀀스 $\left(\mathbf{y_i} \right)^m_1$를 생성합니다. $\mathbf{y}_i\in\mathbb{R}^v$는 토큰에 대한 원핫벡터이며 $i, v$는 토큰 vocabulary의 사이즈입니다. 마지막으로 m은 하이퍼파라미터입니다. 논문에서는 multilingual BART의 처음 4개의 레이어를 디코더 architecture로 사용했습니다.
Model Input
모델은 지도학습 방식으로 학습되었으며, 테스트 단계에선 GPT-3처럼 주어진 prompt에 따라 토큰 시퀀스를 생성합니다. 따라서 단순히 prompt를 위한 special 토큰들을 제공하여 각각의 downstream task들을 처리합니다. Figure 3에서 나타난 것 처럼 [START_Parsing], [START_Classification] 등의 prompt들을 사용합니다.
Output Conversion
출력된 토큰 시퀀스들은 1대1로 JSON 포맷으로 변환되어 저장됩니다.(Figure 3 참조)
Pre-training
앞에서 언급했듯이 현재 VDU에서 SoTA 모델은 학습시에 큰 스케일의 실제 문서 이미지들에 의존하고 있습니다. 하지만 실제로 이런 방법이 항상 가능한건 아닙니다. 특히 영어를 제외한 다양한 언어에 대해 적용하기 쉽지 않습니다.
Synthetic Document Generator

논문에서는 이러한 문제를 해결하기 위해서 문서를 합성해 데이터셋을 만드는 pipeline인 SynthDoG를 같이 제안합니다. Figure 4에서 나타나듯이 생성된 이미지는 배경, 문서, 텍스트, 레이아웃 등의 요소로 구성되어 있으며 랜덤 패턴 등을 적용하여 pre-train에 필요한 데이터셋을 생성하게 됩니다. SynthDoG를 이용해 1.2M개의 문서이미지를 생성했으며 모델을 먼저 이미지 안의 모든 텍스트들을 왼쪽위부터 오른쪽아래 순서대로 읽도록 학습시켰습니다.
Application
모델이 어떻게 읽는지(how to read) 학습한 후, application stage(fine tuning)에서는 모델이 문서이미지를 이해(how to understand)할 수 있도록 학습했습니다. 모든 downstream task들은 JSON 예측 문제처럼 취급하여 적용하게 됩니다.
Deocder는 요구되는 출력 정보를 표현하는 JSON 형식을 생성하도록 훈련됩니다. 예를 들면, 문서 분류 task에서는 디코더는 [START_class] [memo] [END_class]와 같은 토큰 시퀀스를 생성하게 되고 이 시퀀스는 JSON 형식의 {"class": "memo"}와 같이 1대1 변환됩니다.
Expreiments and Analysis

Document Classifcation
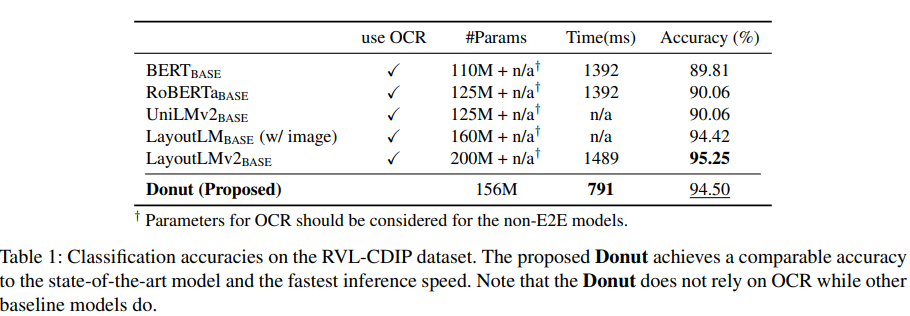
400k의 회색이미지로 구성돼있는 RVL-CDIP 데이터셋을 이용해 문서 분류를 진행하였으며, 다른 모델들이 softmax를 이용해 label을 예측한 것과 달리 Donut은 label 정보를 담은 JSON을 생성합니다. 결과적으로 Donut은 SOTA 모델에 비교해도 상당히 높은 정확도와 빠른 추론속도를 보여줍니다.
Document Parsing

모델이 문서안의 다양한 레이아웃, 형식, 내용 등을 이해하고 있는지 보기 위해 Document Parsing Task를 진행했습니다. normalized Tree Edit Distance(nTED) 점수를 사용해 몇년간 실제 제품으로 사용해왔던 baseline 모델들과 비교했습니다. 결과를 보면 Donut은 가장 높은 nTED 점수를 보임과 동시에 추론시간을 의미있게 낮췄습니다.
Document VQA
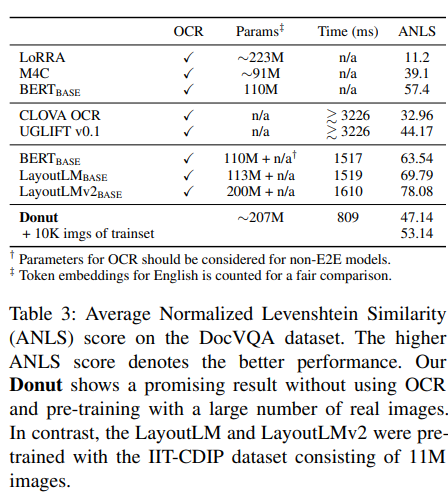
VQA에서는 문서이미지와 자연어 질문이 모델에게 주어지며 Visual, Textual 정보들을 모두 사용하여 적절한 답을 예측해야 합니다. 이 task 역시 방법의 통일성을 유지하기위해서 모델이 질문과 답변을 포함하는 JSON 출력을 생성하게 됩니다. 평가지표(evaluation metric)은 ANLS(Average Normalized Levenshetein Similarity)를 이용해 측정되었습니다.
Table 3의 첫번째 그룹은 OCR을 활용하는 그룹이며, 두번째 그룹은 텍스트정보를 추출하기 위해서 CLOVA OCR을 이용했습니다. 세번째 그룹은 Microsoft OCR을 이용하였고 LayoutLM과 LayoutLMv2는 large-scale 영어문서 데이터셋에서 사전학습 되었습니다.
표에서 Donut은 합리적인 성능과 빠른 추론속도를 보여준다는 것을 알 수 있습니다. 세번째 그룹의 점수와 Donut의 차이는 실제의 large-scale 데이터셋에서의 pre-training이 영향을 끼친다는 것을 시사합니다. 실제로 Donut을 10K의 DocVQA 데이터셋으로 pre-training 시켰을 경우 상당한 성능향샹(47.14 -> 53.14)를 보여줍니다.
Concluding Remarks
해당 논문에서는 VDU를 위한 새로운 방식의 end-to-end 모델인 Donut을 제안합니다. Donut은 입력 문서이미지를 직접적으로 구조화된 출력으로 맵핑하는 모델입니다. 기존의 전통적인 모델과는 달리, 이 방법은 OCR과 large-scale의 실제 문서이미지들에 의존하지 않습니다. 모델은 학습 pipeline을 이용해 how-to-read를 학습한 뒤 how to understand를 순차적으로 학습하였습니다. 이렇게 학습된 Donut은 VDU task들에 대해서 높은 성능과 동시에 더 나은 비용 효율성을 보여주었습니다.
'AI' 카테고리의 다른 글
| Perceiver IO 논문 리뷰 (0) | 2021.09.24 |
|---|---|
| YOLO v5 Pretrained Pytorch 모델 사용하기 (7) | 2021.03.26 |
| SEER - Pretrainig of Visual Features in the Wild 논문 리뷰 (0) | 2021.03.23 |
| Lambda Networks 논문 리뷰 (0) | 2021.03.02 |
| TransUNet - Transformer를 적용한 Segmentation Model 논문 리뷰 (0) | 2021.02.25 |